ارتباطات ژنتیکی با رشتههای تحصیلی
چکیده
انتخاب رشته تحصیلی بر مسیر شغلی، بهزیستی و توزیع مهارتها در جامعه تأثیرگذار است، اما تأثیرات ژنتیکی بر رشتهای که افراد انتخاب میکنند هنوز به خوبی درک نشده است. در این پژوهش، با استفاده از مطالعات همخوانی سراسر ژنوم (GWAS) بر روی ۴۶۳٬۱۳۴ نفر از فنلاند، نروژ و هلند (با حجم نمونه مؤثر بین ۴۰٬۰۷۲ تا ۳۱۷٬۲۰۹)، نشان میدهیم که عوامل ژنتیکی با تخصصهای رشتههای تحصیلی در ارتباط هستند. ما ۱۷ واریانت مستقل با اهمیت آماری در سطح ژنوم را شناسایی کردیم که با ۷ رشته از ۱۰ رشته تحصیلی مورد بررسی مرتبط بودند و میانگین وراثتپذیری آنها ۷٪ بود. این سیگنال ژنتیکی مختص انتخاب رشته است و نه سطح تحصیلات، و حتی پس از کنترل سالهای تحصیل و عوامل مخدوشگر نیز پایدار باقی میماند. با بررسی خوشهبندی ژنتیکی در میان تخصصها، دو بعد کلیدی را کشف کردیم: فنی در برابر اجتماعی و عملی در برابر انتزاعی. ما مطالعات GWAS را بر روی این مؤلفهها انجام دادیم و همبستگیهای ژنتیکی متمایزی را با شخصیت، رفتار و وضعیت اجتماعی-اقتصادی نشان دادیم. یافتههای ما نشان میدهد که پژوهشهای ژنومیک میتوانند «قشربندی افقی» را روشن سازند و دیدگاههای جدیدی در مورد علایق شغلی و طبقهبندی اجتماعی فراتر از معیارهای سنتی پیشرفت تحصیلی ارائه دهند.
مقدمه
تحصیلات، عنصری بنیادی در اقتصاد، فرهنگ و نظامهای قشربندی اجتماعی جوامع مدرن است. تحقیقات گستردهای، تحصیلات را به طیف وسیعی از پیامدها، از جمله حوزههای شغلی، فرهنگی و سلامت مرتبط دانستهاند.
اگرچه اغلب بر سالهای تحصیل تمرکز میکنیم، اما نوع تحصیلات نیز به همان اندازه اهمیت دارد. رشتههای تحصیلی، از هنرهای زیبا گرفته تا امور مالی، بسیار متنوع هستند و درجات مختلفی از مهارتهای فرهنگی، اقتصادی، فنی و ارتباطی را در بر میگیرند. دانشجویان مهندسی معمولاً درآمد بیشتری نسبت به فارغالتحصیلان علوم انسانی دارند، حتی با سطح تحصیلات مشابه. تخصصهای رشتهای بر همه چیز، از نگرشها و باروری گرفته تا شبکههای اجتماعی و بازارهای ازدواج در نسلهای مختلف، تأثیر میگذارند. این «قشربندی افقی» – تفاوت در مسیرهای تحصیلی با وجود سالهای تحصیل مشابه – بخش مهمی از داستان را بیان میکند که معیارهای عمودی از آن غافلاند. گسترش انبوه نظامهای آموزشی، انتخاب رشته را به طور فزایندهای برجسته کرده است. با تضعیف ارزش سیگنالدهی سطح تحصیلات، اهمیت رشته تحصیلی فرد افزایش یافته است.
انتخابهای تحصیلی از الگوهای اجتماعی پیروی میکنند. زنان در رشتههای مراقبتی مانند پرستاری و مددکاری اجتماعی حضور بیشتری دارند، در حالی که مردان در رشتههای فنی مانند مهندسی و مالی بیشتر دیده میشوند. به طور کلی، مشاغل تحت سلطه مردان دستمزد بالاتری دارند. گفته شده است که این الگوها به دلیل اجتماعی شدن، زمینهسازی، جایگاه اجتماعی، هنجارهای جنسیتی و کلیشههای فرهنگی حفظ میشوند. سوابق تحصیلی والدین، انتخاب رشته فرزندانشان را به شدت پیشبینی میکند و دانشجویانی که از خانوادههای تحصیلکردهتر هستند، مشاغلی با ریسک مالی بالاتر را انتخاب میکنند. عوامل جغرافیایی مانند تفاوتهای شهری-روستایی نیز بر هنجارهای انتخاب و دسترسی به رشتههای خاص تأثیر میگذارند.
فراتر از عوامل اجتماعی، روانشناسی فردی از طریق تمایلات رفتاری نظاممند، علایق شغلی و باورها در مورد چشماندازهای آینده، در طبقهبندی افراد در رشتهها نقش دارد. برای مثال، افراد برونگراتر به سمت رشتههایی گرایش پیدا میکنند که فرصتهای تماس اجتماعی فراهم میکنند، مانند مراقبتهای بهداشتی، و سطوح بالاتری از گشودگی به تجربه در میان دانشجویان هنر، علوم انسانی و روانشناسی مشاهده میشود.
مطالعات پیشین تلاش کردهاند تا با اندازهگیری ترجیحات برای پاداشهای درونی در مقابل بیرونی یا ویژگیهای کارآفرینانه در مقابل بوروکراتیک، سازوکارهای انتخاب را شناسایی کنند. با این حال، این معیارهای ترجیحی معمولاً تنها در نمونههای کوچک در دسترس هستند، واریانس کمی را توضیح میدهند و به ندرت انتخابهای واقعی رشته را شامل میشوند. یک رویکرد جامع مبتنی بر داده برای درک ساختار رشتههای تحصیلی، استفاده از تکنیکهای چندمتغیره کاهشبعد بر روی انتخابهای واقعی رشته است. اما این کار دشوار است، زیرا یک فرد معمولاً فقط در یک رشته تحصیل میکند.
با توجه به اینکه صفات مختلف مرتبط با رشتههای تحصیلی وراثتپذیر هستند، احتمالاً خود رشتههای تحصیلی نیز چنیناند. واریانتهای ژنتیکی ممکن است به طرق مختلفی با انتخاب رشته مرتبط باشند. ممکن است همبستگیهای فعال ژن-محیط (rGEs) وجود داشته باشد، که در آن افراد تجربیات خود را مطابق با صفات وراثتی خود انتخاب میکنند. همبستگیهای برانگیزاننده ژن-محیط (Evocative rGEs) زمانی به وجود میآیند که افراد به دلیل صفات وراثتی خود به سمت رشتههای خاصی تشویق میشوند. تأثیر ژنتیکی در مطالعات دوقلوها بر روی علایق و انتخابهای شغلی، مانند مشاغل خلاق، و انتخاب دروس مدرسه نشان داده شده است، جایی که تخمینهای وراثتپذیری برای علوم انسانی حدود ۵۰٪ و برای علوم، فناوری، مهندسی و ریاضیات (STEM) حدود ۶۰٪ است. با این حال، ارتباطات ژنتیکی در سطح جمعیت با رشتههای تحصیلی متنوع با استفاده از روشهای مدرن ژنومیک هنوز مورد مطالعه قرار نگرفته است.
رویکردهای ژنومیک مزایای منحصربهفردی برای مطالعه رشتههای تحصیلی دارند. اولاً، آنها میتوانند با تخمین ساختارهای کوواریانس ژنتیکی با استفاده از آمار خلاصه مطالعات همخوانی سراسر ژنوم (GWAS)، ابعاد مشترک زیربنایی انتخاب رشته را شناسایی کنند. این کار حتی زمانی که نمونههای مطالعه برای هر پیامد همپوشانی ندارند، مانند زمانی که افراد فقط در یک رشته مشاهده میشوند، قابل انجام است. این امر امکان شناسایی تعداد کمتری از مؤلفهها را فراهم میکند که ساختار کوواریانس انتخابهای رشته تحصیلی را توضیح میدهند. ثانیاً، دادههای ژنومیک برای استنتاج علی در هنگام مطالعه در بستر اجتماعی ارزشمند هستند. ارتباطات سادهانگارانه بین واریانتهای ژنتیکی و پیامدهای تحصیلی نه تنها شامل اثرات ژنتیکی مستقیم (اثرات DNA خود فرد بر انتخاب رشتهاش، که از طریق همبستگیهای فعال و برانگیزاننده ژن-محیط عمل میکند) بلکه شامل عوامل مخدوشگر ناشی از همبستگی با تأثیرات محیطی (همبستگیهای غیرفعال ژن-محیط) نیز میشود. عوامل مخدوشگر احتمالی شامل اثرات ژنتیکی غیرمستقیم ژنوم بستگان بر انتخاب رشته فرد مورد نظر، قشربندی جغرافیایی و اجتماعی، به عنوان مثال، به دلیل سیاستهای آموزشی منطقهای و قشربندی جمعیت (در نتیجه تفاوت فراوانی آللها در میان زیرجمعیتها) است. با قرار دادن دادههای ژنتیکی افراد در بستر خانوادگی و جغرافیاییشان، میتوان این سازوکارها را از هم تفکیک کرد. سهم نسبی ارتباطات ژنتیکی مستقیم در مقابل غیرمستقیم با انتخاب رشته هنوز مشخص نشده است.
علاوه بر این، مطالعه رشتههای تحصیلی میتواند پژوهشهای ژنومیک در مورد قشربندی اجتماعی را غنیتر کند. پژوهشهای ژنومیک در مورد جایگاه عمودی مرسوم در پیشرفت تحصیلی، درآمد و وضعیت شغلی، تنوع علایق و مهارتهایی را که مسیرهای تحصیلی در بر میگیرند و محدودیتها و پیامدهای مهم این مسیرها را نادیده میگیرد. ارتباطات ژنتیکی با رشتههای مختلف تحصیلی بعید است که به طور کامل توسط همبستگیهای ژنتیکی شناختهشده وضعیت اجتماعی-اقتصادی توضیح داده شوند و بنابراین ممکن است به بینشهای جدیدی در مورد چگونگی ترکیب عوامل فردی و زمینهای برای تأثیرگذاری بر فرصتهای زندگی منجر شوند.
در اینجا ما با استفاده از دادههای سراسری جمعیت از فنلاند، نروژ و هلند، ارتباطات ژنتیکی با ده رشته تحصیلی گسترده را مطالعه کردیم. اول، بررسی کردیم که آیا عوامل ژنتیکی مستقل از سطح تحصیلات با رشتههای تحصیلی مرتبط هستند یا خیر. دوم، ارتباطات ژنتیکی مستقیم را از ارتباطات مخدوشگر با استفاده از دادههای درون-خانوادگی و جغرافیایی جدا کردیم. سوم، توصیف تجربی از خوشهبندی مرتبط با ژنتیک در رشتههای تحصیلی ارائه دادیم و الگوهای کلیدی (مؤلفههای اصلی (PCs)) طبقهبندی در رشتهها را خلاصه کردیم. چهارم، دامنه پژوهش در مورد نقش رشتههای تحصیلی در علوم اجتماعی و علوم زیستی را از طریق تحلیلهای همبستگی ژنتیکی در سطح فِنوم (phenome-wide) گسترش دادیم.
صلاحیتهای تحصیلی پیامدهای پیچیدهای هستند که نه تنها تحت تأثیر صفات، علایق و مهارتهای فردی، بلکه تحت تأثیر موانع و حمایتهای اجتماعی متعدد نیز قرار دارند. تحلیلهای ما بر کشورهای نوردیک متمرکز است که در آنها تحصیل رایگان و امنیت اجتماعی بالاست. بنابراین، نتایج احتمالاً بیشتر منعکسکننده علایق و ترجیحات فردی هستند تا منابع خانوادگی یا محدودیتهای مالی، اگرچه موانع اجتماعی حتی در این محیطهای برابرطلبانه نیز پابرجا هستند.
نتایج
ارتباطات ژنتیکی با ده رشته تحصیلی
ما دادههای اداری سراسری جمعیت از ثبتهای آموزشی نروژ و فنلاند را برای بزرگسالان ۲۵ سال به بالا تحلیل کردیم که شامل ده رشته گسترده تعریفشده توسط طبقهبندی استاندارد بینالمللی آموزش (ISCED) بود. ما دادههای مربوط به بالاترین مدرک تحصیلی افراد تا سال ۲۰۱۸ را استخراج کردیم که شامل مدارک در تمام سطوح بود. پس از پیوند دادن دادههای ثبتی به دادههای ژنوتیپ در مطالعه کوهورت مادر، پدر و کودک نروژ (MoBa) و FinnGen و انجام مطالعات GWAS، ما فراتحلیلهای وزندهیشده بر اساس حجم نمونه را با METAL انجام دادیم. مجموع حجم نمونههای مؤثر برای مهندسی، تولید و ساختوساز ۳۱۷٬۲۰۹، برای بهداشت و رفاه ۲۹۲٬۹۲۹، برای تجارت، مدیریت و حقوق ۲۶۱٬۱۸۲، برای خدمات (شامل حملونقل، امنیت و خدمات شخصی) ۱۶۸٬۱۵۷، برای آموزش ۱۰۲٬۹۷۰، برای هنر و علوم انسانی ۹۷٬۲۶۲، برای علوم اجتماعی، روزنامهنگاری و اطلاعات ۶۹٬۱۲۳، برای کشاورزی، جنگلداری، شیلات و دامپزشکی ۶۳٬۸۳۴، برای فناوریهای اطلاعات و ارتباطات (ICTs) ۵۰٬۸۱۹ و برای علوم طبیعی، ریاضیات و آمار ۴۰٬۰۷۲ بود. حجم نمونه جمعیت و کوهورت، به علاوه حجم نمونههای مؤثر برای مطالعات GWAS، در جدول تکمیلی ۱ نشان داده شده است.
ما ۱۷ پلیمورفیسم تکنوکلئوتیدی (SNP) مستقل با اهمیت آماری در سطح ژنوم را در ۷ رشته شناسایی کردیم که بیشترین ارتباطات (۴ لوکوس) مربوط به بهداشت و رفاه بود و چندین رشته دیگر هر کدام ۱ تا ۳ لوکوس داشتند (جدول تکمیلی ۲الف). تمام لوکوسهای معنادار مختص یک رشته خاص بودند. نمودارهای منهتن و نمودارهای کوانتیل-کوانتیل در شکلهای تکمیلی ۱-۲۰ نشان داده شدهاند. ارتباطات SNP شناساییشده برای رشتههایی با حجم نمونه کمتر (مانند علوم طبیعی، ریاضیات و آمار) به احتمال زیاد مثبت کاذب هستند.
تخمینهای وراثتپذیری SNP در مقیاس مسئولیت (liability-scale) که با استفاده از رگرسیون امتیاز عدم تعادل پیوستگی (LD) محاسبه شد، به طور متوسط ۷٪ (میانه ۵٪) بود و از ۳٪ (بهداشت و رفاه) تا ۱۴٪ (علوم طبیعی، ریاضیات و آمار) متغیر بود (شکل ۱ و جدول تکمیلی ۳). تخمینهای وراثتپذیری SNP در کوهورتهای مختلف سازگار بود و همبستگیهای ژنتیکی به طور کلی بیشتر از ۰.۷۵ بود (جداول تکمیلی ۴ و ۵).
ارتباطات ژنتیکی مستقل از سطح تحصیلات وجود دارد
دو رویکرد تأیید کردند که ارتباطات ژنتیکی منعکسکننده خودِ انتخاب رشته است، نه فقط سطح تحصیلات. شکل ۱ نشان میدهد که پس از کنترل سطح تحصیلات (EA) به عنوان یک متغیر کمکی، میانگین وراثتپذیری SNP از ۷٪ به ۴٪ کاهش یافت. تحلیلهای GWAS-تفریقی در مدلسازی معادلات ساختاری ژنومیک (SEM؛ با استفاده از بزرگترین GWAS خارجی موجود برای EA) نتایج مشابهی با میانه وراثتپذیری SNP ۳٪ به دست داد (جدول تکمیلی ۶). پنج ارتباط SNP پس از تعدیل EA معنادار باقی ماندند (جدول تکمیلی ۲، ب)، و مدلهای SEM ژنومیک واریانس معنادار مختص رشته را تأیید کردند (جدول تکمیلی ۷). همبستگیهای ژنتیکی بین EA و رشتهها نشان داد که رویه تعدیل برای اکثر رشتهها موفقیتآمیز بوده است، اگرچه مقداری از واریانس EA برای علوم طبیعی و علوم اجتماعی باقی مانده بود (هر دو با همبستگی ژنتیکی حدود ۰.۳ با EA؛ جدول تکمیلی ۸). مگر اینکه خلاف آن ذکر شده باشد، ما بر نتایج GWAS تعدیلنشده تمرکز کردیم. بحث دقیق در مورد روابط علی متقابل و روشهای تعدیل در یادداشتهای تکمیلی و شکل تکمیلی ۲۱ آمده است و توزیعهای EA مختص هر رشته در شکلهای تکمیلی ۲۲ و ۲۳ و جدول تکمیلی ۹ نشان داده شده است.
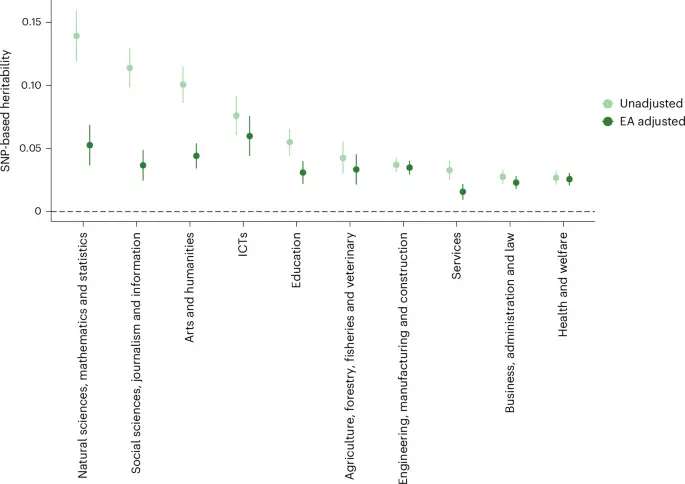
دادهها به صورت تخمین نقطهای ± خطای استاندارد ارائه شدهاند. تحلیل آماری از رگرسیون امتیاز LD با آزمونهای دوطرفه استفاده کرده است. حجم نمونه کل ۴۶۳٬۱۳۴ نفر بود و تعداد «موارد» از ۱۰٬۲۵۲ برای علوم طبیعی، ریاضیات و آمار تا ۱۰۲٬۸۷۴ برای مهندسی، تولید و ساختوساز متغیر بود. مجموع حجم نمونههای مؤثر برای مهندسی، تولید و ساختوساز ۳۱۷٬۲۰۹، برای بهداشت و رفاه ۲۹۲٬۹۲۹، برای تجارت، مدیریت و حقوق ۲۶۱٬۱۸۲، برای خدمات ۱۶۸٬۱۵۷، برای آموزش ۱۰۲٬۹۷۰، برای هنر و علوم انسانی ۹۷٬۲۶۲، برای علوم اجتماعی، روزنامهنگاری و اطلاعات ۶۹٬۱۲۳، برای کشاورزی، جنگلداری، شیلات و دامپزشکی ۶۳٬۸۳۴، برای ICTs ۵۰٬۸۱۹ و برای علوم طبیعی، ریاضیات و آمار ۴۰٬۰۷۲ بود. سطح تحصیلات به عنوان یک متغیر کمکی تعدیل شد.
ارتباطات ژنتیکی، اثرات ژنتیکی مستقیم را نشان میدهند
ارتباطات ژنتیکی در سطح جمعیت با انتخاب رشته ممکن است نه تنها منعکسکننده اثرات ژنتیکی مستقیم، بلکه اثرات ژنتیکی غیرمستقیم، تأثیرات جغرافیایی و قشربندی جمعیت نیز باشد. اگرچه اینها شامل اثرات علی محیطی هستند، اما هنگام تخمین اثرات ژنتیکی مستقیم، به عنوان عوامل مخدوشگر عمل میکنند. ما از دو رویکرد مختلف برای درک سهم نسبی اثرات ژنتیکی غیرمستقیم در یافتههای اصلی خود استفاده کردیم.
در کوهورت مستقل Lifelines (تعداد = ۳۶٬۵۰۱)، ۸ از ۱۰ شاخص چندژنی (PGIs) با رشتههای مربوطه خود در سطح P < ۰.۰۰۵ مرتبط بودند (جدول تکمیلی ۱۰)، اگرچه اندازههای اثر کوچک تا ناچیز بود. بزرگترین ارتباطات برای هنر و علوم انسانی (تغییر در لگاریتم شانس = ۰.۲۲، خطای استاندارد = ۰.۰۳ و R² = ۰.۰۰۵۲۹، که R² ضریب تعیین کاذب برای مدل لجستیک است) و علوم طبیعی، ریاضیات و آمار (تغییر در لگاریتم شانس = ۰.۱۷، خطای استاندارد = ۰.۰۴، R² = ۰.۰۰۲۸۳) بود. سپس، در یک زیرنمونه از ۱۷٬۷۰۵ فرد، ما مجموع شاخصهای PGI والدین آنها را به عنوان یک متغیر کنترل وارد کردیم. این کار از تنوع ژنتیکی تصادفی درون خانواده برای تخمین اثرات ژنتیکی مستقیم بدون عوامل مخدوشگر بهره برد. اثرات ژنتیکی مستقیم به طور معناداری با تخمینهای جمعیتی تفاوت نداشت، که نشاندهنده عدم وجود شواهد برای اثرات ژنتیکی غیرمستقیم بر ارتباطات جمعیتی است (شکل ۲ و جدول تکمیلی ۱۱؛ نتایج بوتاسترپ را در جدول تکمیلی ۱۲ ببینید). با این حال، توان آماری برای تحلیلهای درون خانواده در زیرنمونه کمتر بود و تنها دو ارتباط PGI-رشته در سطح P < ۰.۰۰۵ از نظر آماری معنادار باقی ماندند. نتایج هنگام استفاده از مدلهای خطی به جای لجستیک مشابه بود (جداول تکمیلی ۱۳ و ۱۴).
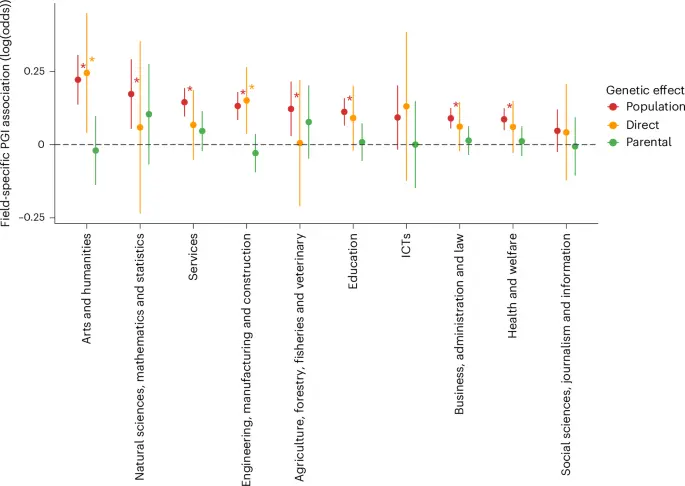
دادهها به صورت تخمین اثر با بازههای اطمینان ۹۹.۵٪ ارائه شدهاند. تحلیل آماری از رگرسیون لجستیک با آزمونهای دوطرفه استفاده کرده است. مقایسههای چندگانه با استفاده از تصحیح بونفرونی (α = ۰.۰۰۵ برای ۱۰ فرضیه؛ * نشاندهنده اهمیت آماری در سطح ۰.۰۰۵ است) تعدیل شدند (تعداد = ۳۶٬۵۰۱ برای تخمین اثرات جمعیتی و ۱۷٬۷۰۵ برای تخمین اثرات ژنتیکی مستقیم و اثرات ژنتیکی غیرمستقیم والدین). اثرات ژنتیکی مستقیم، تخمینهای علی درون خانواده هستند، در حالی که اثرات ژنتیکی غیرمستقیم والدین میتوانند تحت تأثیر قشربندی جمعیت و سایر همبستگیهای ژن-محیط قرار گیرند. ارتباطات معنادار PGI درون خانواده برای هنر و علوم انسانی (تغییر در لگاریتم شانس = ۰.۲۴۵، P = ۰.۰۰۰۸) و مهندسی، تولید و ساختوساز (تغییر در لگاریتم شانس = ۰.۱۵، P = ۰.۰۰۰۲) مشاهده شد.
علاوه بر این، ما همسرگزینی همسان در زمینه رشتههای تحصیلی را بررسی کردیم. ما آزمایش کردیم که آیا همان شاخصهای PGI رشته تحصیلی همسر یا شریک زندگی فرد را پیشبینی میکنند (تعداد = ۲۸٬۵۸۱). برای رشتههای آموزش، هنر و علوم انسانی، و خدمات، شاخص PGI با رشته تحصیلی همسر یا شریک زندگی در سطح P < ۰.۰۰۵ مرتبط است (جدول تکمیلی ۱۵).
ما مطالعات GWAS رشتههای تحصیلی را در MoBa با کنترل (۱) شهرداری محل تولد و (۲) محل تولد و رشتههای تحصیلی والدین انجام دادیم. سپس با استفاده از آمارهای خلاصه حاصل، وراثتپذیری SNP را برای تقریب واریانس ژنتیکی درون-منطقهای و درون-منطقهای-و-خانوادگی محاسبه کردیم. شکل ۳ نشان میدهد که شواهد کمی برای وجود عوامل مخدوشگر وجود داشت: تخمینهای وراثتپذیری پس از افزودن کنترلهای جغرافیایی و والدین به طور قابل توجهی پایینتر نبودند. مدلسازی نسبتهای وراثتپذیری در Genomic SEM طبق مرجع نشان داد که هیچ یک از تخمینهای تعدیلشده به طور معناداری با تخمینهای اصلی تفاوت نداشت، به جز برای علوم اجتماعی، روزنامهنگاری و اطلاعات. برای این رشته، وراثتپذیری SNP از ۱۱٪ به ۷٪ کاهش یافت (P = ۰.۰۳؛ برای نتایج وراثتپذیری و نسبتها و مقادیر P به ترتیب به جداول تکمیلی ۱۶ و ۱۷ مراجعه کنید).
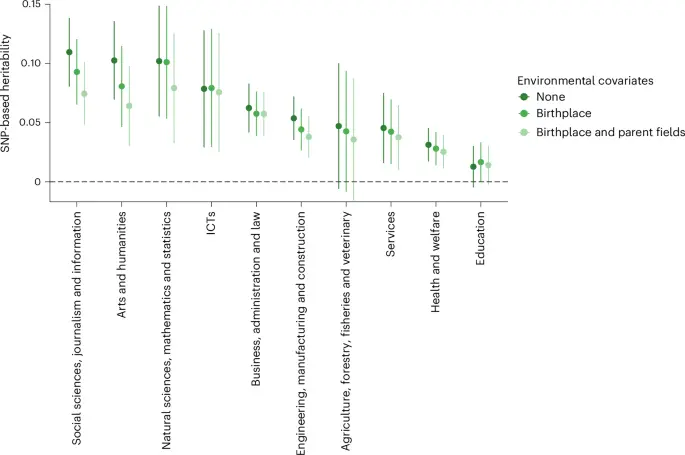
دادهها به صورت تخمین نقطهای با بازههای اطمینان ۹۵٪ ارائه شدهاند. تحلیل آماری از رگرسیون امتیاز LD با آزمونهای دوطرفه استفاده کرده است. مجموع حجم نمونههای مؤثر از ۴۰٬۰۷۲ برای علوم طبیعی، ریاضیات و آمار تا ۳۱۷٬۲۰۹ برای مهندسی، تولید و ساختوساز متغیر بود.
حتی پس از در نظر گرفتن عوامل مخدوشگر محیطی، اثرات ژنتیکی مستقیم از طریق محیط واسطه میشوند (برای توضیح چگونگی اعمال سازوکارهای همبستگی ژن-محیط در اینجا به شکل تکمیلی ۲۴ مراجعه کنید).
مؤلفههای فنی-اجتماعی و عملی-انتزاعی در طبقهبندی افراد
ما طبقهبندی ژنتیکی در رشتههای تحصیلی را از طریق همبستگی ژنتیکی و تحلیل مؤلفههای اصلی (PCA) خلاصه کردیم. ابتدا، همبستگیهای ژنتیکی دوتایی بین رشتهها را با استفاده از نتایج GWAS-تفریقی تخمین زدیم تا مؤلفههای کلیدی مدارک تحصیلی فراتر از سطح تحصیلات را شناسایی کنیم. شکل ۴ نشان میدهد که رشتههای STEM همبستگی مثبتی داشتند (برای مثال، ICTs و علوم طبیعی (همبستگی رتبهای اسپیرمن (rg) = ۰.۵۱، خطای استاندارد = ۰.۱۱))، همانطور که هنر و علوم انسانی با علوم اجتماعی همبستگی داشتند (برای همبستگیهای ژنتیکی بین رشتهها به جدول تکمیلی ۱۸ مراجعه کنید). دوم، برای قابل فهمتر کردن روابط متقابل و شناسایی الگوهای کلیدی طبقهبندی در رشتهها، ما PCA را به کار بردیم. دو محور اول تغییرات (PCs) در مجموع ۶۴٪ از واریانس را توضیح میدهند (برای نتایج PCA به جدول تکمیلی ۱۹ مراجعه کنید). اگرچه تحلیل موازی نشان داد که سه مؤلفه اصلی قابل استخراج هستند (شکل تکمیلی ۲۵)، ما برای سادگی و قابلیت تفسیر بر دو مؤلفه اصلی اول تمرکز کردیم.
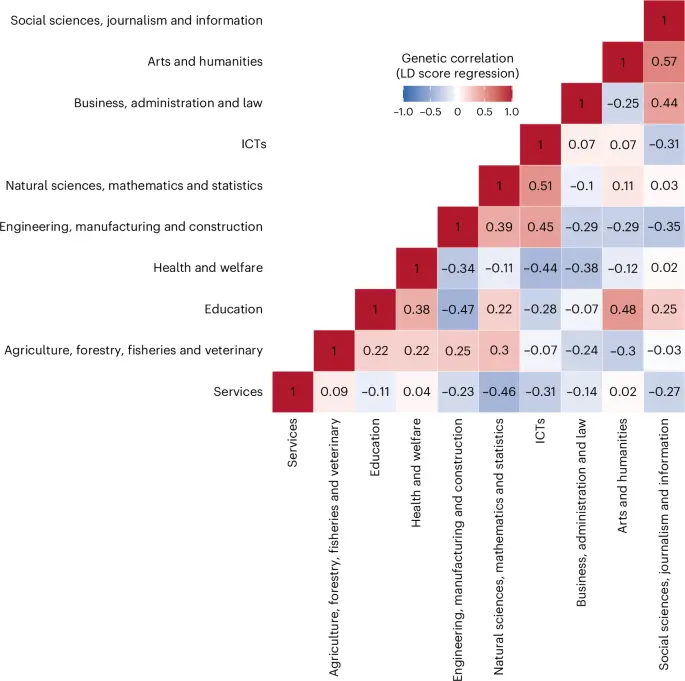
دادهها به صورت ضرایب همبستگی ژنتیکی ارائه شدهاند. تحلیل آماری از رگرسیون امتیاز LD با آزمونهای دوطرفه استفاده کرده است.
شکل ۵ سهم ارتباطات ژنتیکی هر رشته را در دو مؤلفه اصلی اول نشان میدهد. همبستگی بین یک رشته تحصیلی و یک مؤلفه اصلی به عنوان مختصات متغیر روی آن مؤلفه استفاده میشود. مؤلفه اصلی اول (PC1) (محور افقی در شکل ۵)، که ما آن را «فنی در برابر اجتماعی» مینامیم، منعکسکننده تنوع ژنتیکی مرتبط با مدارک در مهندسی، تولید و ساختوساز و علوم طبیعی، ریاضیات و آمار در مقابل آموزش و بهداشت و رفاه است. مؤلفه اصلی دوم (PC2) (محور عمودی در شکل ۵)، که ما آن را «عملی در برابر انتزاعی» مینامیم، منعکسکننده تنوع ژنتیکی مرتبط با مدارک در خدمات و بهداشت و رفاه در مقابل علوم اجتماعی، روزنامهنگاری و اطلاعات و هنر و علوم انسانی است. ساختار همبستگیهای ژنتیکی بین رشتهها بدون کنترل برای سطح تحصیلات در شکل تکمیلی ۲۶ نشان داده شده است.
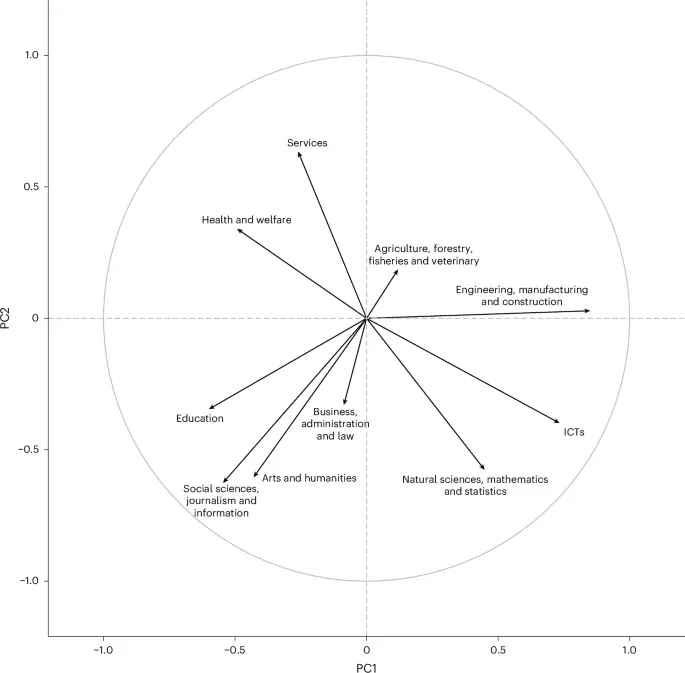
دادهها به صورت بارهای عاملی مؤلفههای اصلی (PC loadings) ارائه شدهاند. تحلیل آماری از PCA استفاده کرده است. متغیرهای با همبستگی مثبت با هم گروهبندی شدهاند و متغیرهای با همبستگی منفی در طرفین مخالف مبدأ نمودار قرار گرفتهاند؛ متغیرهایی که از مبدأ دورتر هستند به خوبی نمایش داده شدهاند. مجموع حجم نمونههای مؤثر به شرح زیر است: برای PC1 = ۱۰٬۴۱۳ و برای PC2 = ۷٬۳۵۳.
ما مطالعات GWAS مؤلفههای اصلی را انجام دادیم (طبق مرجع). PC1 شش ارتباط SNP با اهمیت آماری در سطح ژنوم نشان داد و PC2 هیچ ارتباطی نشان نداد (برای SNPهای اصلی به جدول تکمیلی ۲ج، برای نمودارهای منهتن به شکلهای تکمیلی ۲۷ و ۲۸ و برای همبستگیهای ژنتیکی بین مؤلفههای اصلی و رشتههای تحصیلی منفرد به جدول تکمیلی ۱۸ مراجعه کنید).
همبستگیهای ژنتیکی دو مؤلفه اصلی
شکل ۶ همبستگیهای ژنتیکی با این دو مؤلفه اصلی و ۹۶ فنوتیپ انسانی در سطح فِنوم را نشان میدهد که حوزههایی از جمله شخصیت، سلامت روان، مصرف مواد، سلامت و باروری را در بر میگیرد (جدول تکمیلی ۲۰).
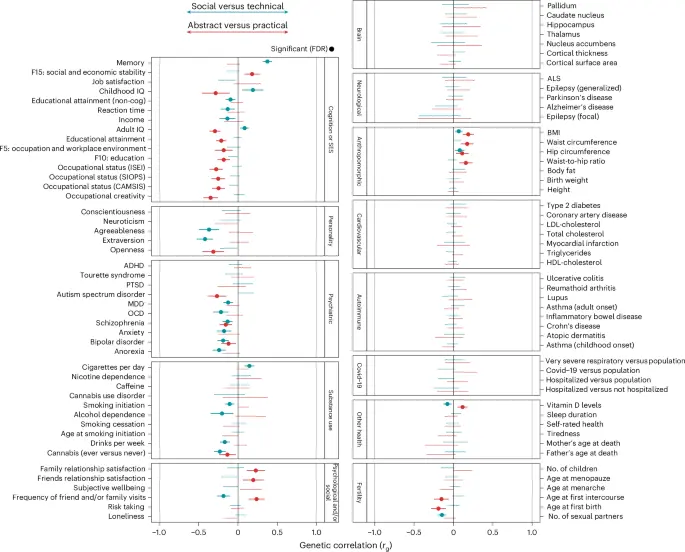
دادهها به صورت ضرایب همبستگی با بازههای اطمینان ۹۵٪ ارائه شدهاند. تحلیل آماری از رگرسیون امتیاز LD با آزمونهای دوطرفه استفاده کرده است. تصحیح FDR برای مقایسههای چندگانه در ۹۶ فنوتیپ اعمال شد. GWASهای رشتههای تحصیلی برای سطح تحصیلات تعدیل شدند. ADHD، اختلال کمتوجهی و/یا بیشفعالی؛ ALS، اسکلروز جانبی آمیوتروفیک؛ BMI، شاخص توده بدنی؛ cog، شناختی؛ FDR، نرخ کشف کاذب؛ HDL، لیپوپروتئین با چگالی بالا؛ LDL، لیپوپروتئین با چگالی پایین؛ MDD، اختلال افسردگی اساسی؛ OCD، اختلال وسواس فکری-عملی؛ PTSD، اختلال استرس پس از سانحه؛ ISEI، شاخص بینالمللی اجتماعی-اقتصادی وضعیت شغلی؛ SIOPS، مقیاس بینالمللی استاندارد اعتبار شغلی؛ CAMSIS، مقیاس تعامل اجتماعی و قشربندی کمبریج.
همبستگی ژنتیکی مثبت با PC1 نشاندهنده ارتباط با رشتههای فنی است، در حالی که همبستگی منفی با PC1 نشاندهنده ارتباط با رشتههای اجتماعی است. PC1 با برونگرایی و سازگاری همبستگی ژنتیکی منفی داشت (به ترتیب rg = -۰.۴۲ و -۰.۳۷). همبستگیهای ژنتیکی منفی معناداری نیز با مصرف آزمایشی حشیش (rg = -۰.۲۳)، وابستگی به الکل (rg = -۰.۲۰) و شش تشخیص روانپزشکی (میانگین rg = -۰.۱۸) مشاهده شد، در حالی که همبستگی ژنتیکی با تعداد سیگار در روز مثبت بود (rg = ۰.۱۴). PC1 با حافظه و ضریب هوشی کودکی و بزرگسالی همبستگی ژنتیکی مثبت داشت (به ترتیب rg = ۰.۳۷ و ۰.۱۹)، اما با درآمد و مهارتهای غیرشناختی همبستگی ژنتیکی منفی داشت (به ترتیب rg = -۰.۱۳ و -۰.۱۰).
همبستگی ژنتیکی مثبت با PC2 نشاندهنده ارتباط با رشتههای عملی است، در حالی که همبستگی منفی با PC2 نشاندهنده ارتباط با رشتههای تحصیلی انتزاعی است. PC2 با شخصیت باز، اوتیسم، اسکیزوفرنی، اختلال دوقطبی و مصرف آزمایشی حشیش همبستگی ژنتیکی منفی داشت (به ترتیب rg = -۰.۳۱، -۰.۲۷، -۰.۱۶، -۰.۱۲ و -۰.۱۳). همبستگیهای ژنتیکی منفی نیز با دو شاخص باروری مشاهده شد: سن در اولین تولد و سن در اولین رابطه جنسی (rg = -۰.۱۹ و -۰.۱۵). PC2 با ملاقات دوستان یا خانواده و رضایت از روابط خانوادگی همبستگی ژنتیکی مثبت داشت (rg = ۰.۲۴ و ۰.۲۳) و با شاخص توده بدنی بالاتر و نسبت دور کمر به باسن (rg = ۰.۱۹ و ۰.۱۷).
اگرچه آمارهای خلاصه PC2 برای سطح تحصیلات با استفاده از GWAS تفریقی تعدیل شده بودند، PC2 همچنان به طور معناداری با وضعیت شغلی، سطح تحصیلات و ضریب هوشی کودکی همبستگی ژنتیکی (منفی) دارد (rg = -۰.۲۶، -۰.۲۱، -۰.۲۹)، و همچنین با خلاقیت شغلی (rg = -۰.۳۵). قابل ذکر است که PC2 با یک عامل پنهان که ثبات اجتماعی و اقتصادی را در Biobank بریتانیا نشان میدهد، همبستگی ژنتیکی مثبت داشت (rg = ۰.۱۸؛ این به اصطلاح عامل ۱۵ به شبکههای حمایت اجتماعی، تنهایی، مالکیت خانه، درآمد خانوار و هرگز طلاق نگرفتن مربوط میشود)، اما با دو عامل دیگر که نماینده شغل یا محیط کار (F5) و سطح تحصیلات (F10) هستند، همبستگی منفی داشت (rg = -۰.۱۸ برای هر دو).
شواهد محدود برای تفاوتهای جنسیتی
مؤلفه اجتماعی-فنی (PC1) تفکیک جنسیتی قوی نشان میدهد: ۸۴٪ از مدارک مهندسی به مردان و ۸۸٪ از مدارک بهداشت و رفاه به زنان تعلق دارد (شکل تکمیلی ۲۹). برای بررسی نقش جنسیت در ساختار ارتباطات ژنتیکی با رشتههای تحصیلی، ما دو تحلیل انجام دادیم. اول، PCA را با حذف رشتههایی که به شدت دارای سوگیری جنسیتی بودند (≥۷۰٪ یک جنس: مهندسی، بهداشت و آموزش) تکرار کردیم. دوم، GWASهای تفکیکشده بر اساس جنسیت انجام دادیم و PCA را تکرار کردیم. هر دو تحلیل ساختار ژنتیکی سازگاری را در بین جنسیتها نشان دادند (شکلهای تکمیلی ۳۰-۳۲). تخمینهای وراثتپذیری SNP بین مردان و زنان مشابه بود، اما همبستگیهای ژنتیکی بین دو جنس به طور گستردهای از ۰.۱۷ (مهندسی) تا ۰.۷۲ (علوم طبیعی) متغیر بود (جدول تکمیلی ۲۱). با این حال، چندین عامل نتیجهگیریهای قوی در مورد تفاوتهای جنسیتی را محدود میکنند. حجم نمونه برای تحلیلهای مختص جنسیت پایین بود (حداقل ۹۵۲ مورد ICT برای زنان) و رشتههای گسترده شامل زیررشتههای ناهمگنی با توزیع جنسیتی متفاوت هستند. همبستگیهای ژنتیکی پایین ممکن است منعکسکننده صفات وراثتی متفاوت برای انتخاب زیررشتهها (به عنوان مثال، ساختوساز در مقابل مهندسی) باشد تا تفاوتهای جنسیتی بنیادین در ارتباطات ژنتیکی.
بحث
طبقهبندی در رشتههای تحصیلی هم برای افراد و هم برای جامعه مهم است: بر سلامت، بهزیستی و موفقیت، و همچنین دانش و مهارتهای موجود در عرضه نیروی کار تأثیر میگذارد. با استفاده از دادههای سراسری جمعیت از فنلاند و نروژ، ما ارتباطات ژنتیکی با تخصصهای رشتهای را مستقل از سطح تحصیلات نشان دادیم. تحلیلهای درون-خانوادگی در یک کوهورت مستقل هلندی نشان داد که اینها منعکسکننده اثرات ژنتیکی مستقیم هستند نه عوامل مخدوشگر. ما دو بعد کلیدی را کشف کردیم که طبقهبندی در رشتهها را توصیف میکنند: فنی در برابر اجتماعی و عملی در برابر انتزاعی. همبستگیهای ژنتیکی گسترده بین این مؤلفهها و شخصیت، باروری، سلامت روان، مصرف مواد و وضعیت اجتماعی-اقتصادی، فرضیههای فراوانی را برای تحلیلهای بعدی در مورد علایق شغلی و قشربندی افقی فراهم میکند.
ما دریافتیم که تخمینهای وراثتپذیری SNP برای انتخاب رشته تحصیلی به طور متوسط ۷٪ است. اینها تخمینهای حداقل از نقش عوامل ژنتیکی هستند زیرا روش ما فقط اثرات تجمعی واریانتهای رایج را که توسط آرایههای ژنوتیپسنجی مشخص میشوند، در بر میگیرد، نه کل وراثتپذیری با مفهوم گسترده (مشکل وراثتپذیری گمشده). در دو رویکرد مختلف، یعنی ارتباطات PGI درون-خانوادگی و GWASهای با کنترل محل تولد و رشتههای والدین، ما شواهدی برای مخدوش شدن اثرات ژنتیکی مشاهده نکردیم. با این حال، فقدان توان آماری برای تحلیلهای درون-خانوادگی ما را از نتیجهگیریهای قوی باز داشت و نتایج همبستگی ژنتیکی نشاندهنده تعامل قابل توجه با عوامل اجتماعی-اقتصادی بود. مطالعات آینده در مقیاس بزرگ و مبتنی بر خانواده باید این اثرات را کمیسازی کنند. با توجه به نتایج خودمان و شواهد جامعهشناختی پیشین مبنی بر اینکه بازتولید خانوادگی انتخاب رشته یک کانال انتقال مستقل از سطح تحصیلات است، اثرات ژنتیکی غیرمستقیم بر انتخاب رشته تحصیلی ممکن است کوچکتر از اثرات آن بر سطح تحصیلات باشد. با این وجود، عوامل محیطی والدین احتمالاً میانجیهای کلیدی اثرات ژنتیکی مستقیم هستند.
تحلیل ژنتیکی روابطی را آشکار کرد که مطالعه آنها به صورت فنوتیپی دشوار است، مانند همپوشانی بین علوم اجتماعی و هنر و علوم انسانی. از طریق کاهش ابعاد همبستگیهای ژنتیکی، ما شواهد جدیدی در مورد الگوهای طبقهبندی در رشتهها ارائه دادیم. ما دو بعد مهم یافتیم: فنی در برابر اجتماعی (PC1) و عملی در برابر انتزاعی (PC2). PC1 منعکسکننده تمایز در رشتههایی است که با اشیاء در مقابل افراد سروکار دارند (مثلاً مهندسی در برابر آموزش)، در حالی که PC2 تمایز در فعالیتهای عملی و کاربردی در مقابل نظری و اکتشافی را نشان میدهد (مثلاً خدمات در برابر علوم اجتماعی). این مؤلفههای اصلی به خوبی با نظریههای اصلی در علوم اجتماعی مطابقت داشتند. مدل علایق شغلی واقعگرا، جستجوگر، هنری، اجتماعی، کارآفرین و قراردادی، که به طور گسترده توسط مشاوران شغلی استفاده میشود، شامل علایق اجتماعی و واقعگرا (مانند PC1) و علایق جستجوگر یا هنری و واقعگرا یا قراردادی (مانند PC2) است. این مؤلفههای اصلی همچنین با نظریه جامعهشناختی که منابع آموزشی اصلی را که افراد در آنها سرمایهگذاری میکنند (ارتباطی، فنی، فرهنگی و اقتصادی) مشخص میکند، مطابقت دارد. این همگرایی بین تحلیل ژنتیکی بدون فرضیه و نظریه علوم اجتماعی، اعتبار جدیدی برای چارچوبهای موجود فراهم میکند. شناسایی الگوهای طبقهبندی اجتماعی بدون نیاز به نظریه یا اندازهگیری مستقیم ترجیحات، نشان میدهد که چگونه رویکردهای ژنتیکی ممکن است مکمل تحقیقات علوم اجتماعی باشند (برای نتایج مشابه در مورد نابرابریهای اجتماعی و بهداشتی، به مرجع مراجعه کنید).
با نشان دادن اینکه چگونه مدارک فنی-اجتماعی و عملی-انتزاعی در سطح ژنتیکی با ۹۶ فنوتیپ انسانی همبستگی دارند، ما دامنه تحقیقات علوم اجتماعی در مورد رشتههای تحصیلی را گسترش دادیم. اگرچه مطالعات، علل و پیامدهای علایق و مدارک تحصیلی، مانند شخصیت، درآمد و باروری را بررسی کردهاند، اما این مطالعات به دلیل دشواری اندازهگیری پیامدهای در سطح فِنوم در مقیاس بزرگ در یک نمونه، محدود بودهاند. بنابراین ما حوزههای جدیدی مانند سلامت روان، مصرف مواد، رضایت از روابط و اندازه بدن را وارد کردیم.
بسیاری از نتایج همبستگی ژنتیکی با این تفسیر سازگار است که مؤلفههای اصلی، علایق شغلی وراثتی افراد را منعکس میکنند. مؤلفه فنی-اجتماعی با صفات اجتماعی که در اوایل زندگی شکل میگیرند مانند برونگرایی، سازگاری و فراوانی دیدارهای اجتماعی، همبستگی ژنتیکی دارد. مؤلفه عملی-انتزاعی تمایلات فردی به سمت شخصیت باز و خلاقیت را نشان میدهد. روابط ژنتیکی مثبت با اسکیزوفرنی و اختلال دوقطبی با شواهدی که نشان میدهد بستگان افراد مبتلا به احتمال بیشتری مشاغل خلاقانه دارند، همخوانی دارد. علایق شغلی و تناسب بین کار فرد و علایقش نقش مهمی در انتخابهای شغلی، بهرهوری و یافتن معنا در زندگی ایفا میکند. شناسایی ارتباطات سراسر ژنوم با علایق به دلیل عدم وجود نمونههای ژنوتیپشده با توان کافی، امکانپذیر نبوده است. ما یک GWAS جدید بر روی یک نماینده (پراکسی) از علاقه از طریق انتخاب رشته تحصیلی ارائه دادیم.
نتایج همچنین الگوهای گستردهتر قشربندی اجتماعی را منعکس میکنند. مؤلفه انتزاعی-عملی (PC2) به شاخصهای سنتی «عمودی» اجتماعی-اقتصادی از جمله وضعیت شغلی مربوط میشود. این ممکن است تا حدی منعکسکننده حذف ناقص واریانس سطح تحصیلات باشد، اگرچه همبستگی ژنتیکی بین PC2 و EA کوچک باقی میماند و رشتههای انتزاعی-عملی به وضوح بر اساس سطح تحصیلات الگو ندارند (حدود ۴۰٪ از فارغالتحصیلان خدمات و کشاورزی دارای مدرک کارشناسی هستند در مقابل ۷۶٪ برای بهداشت و رفاه). بنابراین، این یافتهها ممکن است نشاندهنده این باشند که چگونه منابع اجتماعی و اقتصادی در مسیرهای تحصیلی انتزاعی اهمیت بیشتری دارند. برخلاف رشتههای عملی مانند آموزش و مراقبتهای بهداشتی که به مشاغل دولتی رفاهی گرایش دارند، مدارک انتزاعی اغلب به مشاغل نخبه در رسانهها، سیاست، پژوهش، حقوق و هنر منجر میشوند که معمولاً برای خانوادههای مرفه در دسترستر هستند. جالب است که نتایج ژنتیکی ما تصویر ظریفتری نسبت به شاخصهای مرسوم جایگاه اجتماعی ترسیم میکنند و به طور بالقوه معایب مسیرهای تحصیلی نخبه را شناسایی میکنند: تمایل به رشتههای انتزاعی به جای عملی با بیثباتی اجتماعی-اقتصادی، از جمله تنهایی، طلاق، رضایت کمتر از روابط و خطرات بالاتر اختلالات روانپزشکی مرتبط است.
چرا واریانتهای ژنتیکی با رشته تحصیلی مرتبط هستند؟ در زمینههای نوردیک با تحصیل رایگان و شبکههای ایمنی قوی، اثرات ژنتیکی احتمالاً از طریق ترجیحات و مهارتهای فردی عمل میکنند تا محدودیتهای منابع. با این حال، سازوکارها اساساً اجتماعی باقی میمانند—تمایلات ژنتیکی از طریق همبستگیهای ژن-محیط که از اوایل زندگی آغاز میشوند، با محیطها تعامل دارند. هنجارهای جنسیتی یک میانجی اجتماعی کلیدی هستند، با کلیشههایی که از همان ابتدا بر انتخاب رشته تحصیلی تأثیر میگذارند. به عنوان مثال، هم دختران و هم پسران تمایل دارند از مسیرهای تحصیلی زنانه دور شوند و شکاف جنسیتی در رشتههای STEM تا حدی به دلیل بهرهمندی پسران از سوگیریهای معلمان است. نتایج همچنین میتوانند اثرات پاییندستی پیشنیازهای برنامههای آموزشی را منعکس کنند و ترک تحصیل به دلیل عدم تناسب فرد-محیط یا تبعیض را نشان دهند. نتایج، تأثیرات احتمالی را که از طریق زمینههای اجتماعی واسطه میشوند، منعکس میکنند، نه جبرگرایی ژنتیکی.
همانطور که در سند پرسشهای متداول ما بحث شده است، تفسیرهای جبرگرایانه از ارتباطات ژنتیکی با پیامدهای پیچیدهای مانند رشتههای تحصیلی، اشتباه است. عوامل ژنتیکی تخصصهای رشتهای را تعیین نمیکنند، بلکه به طور احتمالی بر تمایلات افراد تأثیر میگذارند که از طریق تعامل و واسطهگری زمینه اجتماعی و ساختاری، با پیامدهای تحصیلی همبسته میشوند. اگر زمینه اجتماعی تغییر کند، ممکن است ارتباطات ژنتیکی نیز تغییر کنند. عوامل ژنتیکی مرتبط با انتخاب رشته ممکن است متفاوت به نظر برسند اگر افراد تشویق شوند تا طیف وسیعتری از موضوعات را کشف کنند، اگر مهارتهای دخیل در رشتههای خاص متفاوت باشند، یا هنجارهای جنسیتی یا بازده اقتصادی رشتهها تغییر کند. در کشورهایی که نابرابری اجتماعی بیشتر است و پیامدهای اجتماعی-اقتصادی برخی انتخابهای رشتهای پرخطرتر از کشورهای نوردیک است، وراثتپذیری انتخاب رشته ممکن است کمتر باشد و پیوند با علایق و ترجیحات فردی ممکن است کمتر برجسته باشد.
مطالعه ما چندین محدودیت دارد. اول، دستهبندیهای گسترده رشتهای ممکن است سیگنالهای ژنتیکی خاص را پنهان کنند—به عنوان مثال، مهندسی و ساختوساز با وجود گروهبندی با هم، تفاوتهای قابل توجهی دارند. با افزایش حجم نمونه در آینده، مطالعه گروههای همگنتر در دستهبندیهای رشتهای محدودتر با استفاده از روشهای GWAS امکانپذیر خواهد شد. دوم، اگرچه این یک مزیت مطالعه است که ما از دو رویکرد سختگیرانه برای کنترل عوامل مخدوشگر ناشی از همبستگی غیرفعال ژن-محیط و قشربندی جمعیت استفاده کردیم، این تحلیلها توان آماری کافی نداشتند. علاوه بر این، تخمینهای وراثتپذیری SNP تعدیلشده برای محل تولد و رشتههای والدین هنوز هم میتوانند مخدوش باشند اگر رشتههای والدین همبستگی ژنتیکی کاملی با رشتههای فرزندان نداشته باشند (به عنوان مثال، تفاوتهای نسلی) یا تحت تأثیرات اجتماعی بستگان دیگر مانند عمهها، عموها و پسرعموها باشند. سوم، نتایج از جمعیتهای اروپایی در جوامع برابرطلب ممکن است به زمینههای متنوع یا نظامهای رفاهی مختلف تعمیم نیابد. چهارم، اگر یک SNP با بودن در یک رشته ارتباط مثبت داشته باشد، به طور مکانیکی با بودن در رشتههای دیگر ارتباط منفی دارد. کارهای آینده باید بررسی کنند که چگونه این موضوع رگرسیون ظاهراً نامرتبط، ساختار ژنتیکی رشتهها را تحت تأثیر قرار میدهد، به عنوان مثال، از طریق رگرسیون چندجملهای.
این یافتهها مسیرهای تحقیقاتی جدیدی را در زمینه علایق شغلی و قشربندی افقی باز میکنند. ما ابعاد کیفی آموزشی را برای تکمیل ادبیات کمی GWAS در مورد پیشرفتهای تحصیلی و مالی معرفی کردیم. آمارهای خلاصه ما مطالعاتی در مورد توسعه علایق در اوایل زندگی، تعاملات ژن-محیط و اثرات علی انتخاب رشته بر سلامت و درآمد را امکانپذیر میسازد. پیشرفت نیازمند روشهای مبتنی بر خانواده در مقیاس بزرگ است که دیدگاههای بینرشتهای در مورد ترجیحات فردی و هنجارهای اجتماعی را ادغام کند.
برای پاسخ به سؤالات رایج در مورد تفسیر ارتباطات ژنتیکی با رشتههای تحصیلی، به سند پرسشهای متداول ما در یادداشتهای تکمیلی یا به صورت آنلاین در https://www.thehastingscenter.org/genomic-findings-on-social-and-behavioral-outcomes-faqs/ و https://github.com/rosacheesman/Fields_genetics/wiki/Frequently-Asked-Questions-(FAQ) مراجعه کنید.
روشها
اخلاق
این مطالعه با تمام مقررات اخلاقی مربوطه مطابقت دارد. مطالعه کوهورت مادر، پدر و کودک نروژ (MoBa) توسط کمیتههای منطقهای اخلاق در پژوهشهای پزشکی و بهداشتی تأیید شده است (پروتکل شماره 2017/2205) و تحت قانون ثبت سلامت نروژ عمل میکند، و مدیریت دادهها توسط دانشگاه اسلو تحت توافقنامههایی با آمار نروژ انجام میشود. FinnGen تأییدیه کمیته هماهنگکننده اخلاق منطقه بیمارستانی هلسینکی و یوسیما را دریافت کرده است (پروتکل شماره HUS/990/2017)، و شرکتکنندگان تحت قانون بیوبانک فنلاند و چندین مجوز سازمانی از مقامات بهداشتی فنلاند رضایت آگاهانه ارائه دادهاند. Lifelines توسط کمیته اخلاق پزشکی مرکز پزشکی دانشگاه گرونینگن (UMCG) تأیید شده است (2007/152). همه شرکتکنندگان رضایت آگاهانه ارائه دادند و دادهها در امکانات امن مطابق با مقررات ملی حفاظت از دادهها پردازش شدند. برای جزئیات کامل تأییدیههای اخلاقی به یادداشت تکمیلی مراجعه کنید.
زمینهها
تحلیلهای اصلی ما بر اساس دادههای فنلاند و نروژ بود که هر دو دولتهای رفاهی سوسیال دموکرات هستند و با «مدل اسکاندیناوی» آموزش برای همه مطابقت دارند. در مقایسه با سایر کشورهای پردرآمد، نابرابری اقتصادی پایین است و دسترسی به آموزش کمتر توسط موانع اقتصادی محدود میشود. به عنوان مثال، نروژ و فنلاند شهریه رایگان، وامهای مقرونبهصرفه و یارانههای عمومی سخاوتمندانه برای دانشجویان دارند. با این حال، با وجود معکوس شدن شکاف جنسیتی در پیشرفت تحصیلی، تفکیک جنسیتی در رشتههای تحصیلی همچنان ادامه دارد. به همین ترتیب، بازارهای کار نوردیک از جمله جنسیتیترین بازارها هستند.
ما همچنین یک نمونه هلندی را تحلیل کردیم. هلند به عنوان یک دولت رفاهی محافظهکار تعریف شده است. نسبت به دولتهای رفاهی سوسیال دموکرات، قشربندی اجتماعی در آموزش بیشتر است، که تا حدی به دلیل تفکیک زودهنگام تحصیلی و شهریهها است.
نمونهها
FinnGen
FinnGen (https://www.finngen.fi/en)، که در سال ۲۰۱۷ راهاندازی شد، یک پروژه تحقیقاتی عمومی-خصوصی است که دادههای ژنوم و مراقبتهای بهداشتی دیجیتال حدود ۵۰۰٬۰۰۰ فنلاندی را ترکیب میکند. این پروژه تحقیقاتی سراسری با هدف ارائه بینشهای جدید پزشکی و درمانی مرتبط با بیماریهای انسانی انجام میشود. FinnGen یک مشارکت پیشرقابتی از بیوبانکهای فنلاند و سازمانهای پشتیبان آنها (دانشگاهها و بیمارستانهای دانشگاهی) و شرکای صنعت داروسازی بینالمللی و تعاونی بیوبانک فنلاند (FINBB) است. تمام شرکای FinnGen در https://www.finngen.fi/en/partners فهرست شدهاند. این پروژه از دادههای ثبت سلامت طولی سراسری که از سال ۱۹۶۹ از هر ساکن فنلاند جمعآوری شده، استفاده میکند. تحلیلها بر روی افراد بالای ۲۵ سال با دادههای کامل برای ژنوتیپسنجی سراسر ژنوم و سوابق تحصیلی کامل انجام شد.
مطالعه کوهورت مادر، پدر و کودک نروژ
ما بزرگسالانی را که در MoBa شرکت کرده بودند، مطالعه کردیم. MoBa یک مطالعه کوهورت بارداری مبتنی بر جمعیت و آیندهنگر است که توسط مؤسسه بهداشت عمومی نروژ انجام شده است. زنان باردار از سراسر نروژ بین سالهای ۱۹۹۹ تا ۲۰۰۹ جذب شدند. در ۴۱٪ از بارداریها، زنان با شرکت اولیه موافقت کردند. از پدرانی که برای شرکت دعوت شدند، ۸۲.۹٪ موافقت کردند. کل کوهورت شامل تقریباً ۱۱۴٬۵۰۰ کودک، ۹۵٬۲۰۰ مادر و ۷۵٬۲۰۰ پدر است. تحلیلها بر روی والدین MoBa بالای ۲۵ سال با دادههای کامل برای ژنوتیپسنجی سراسر ژنوم و سوابق اداری کامل که از طریق سیستم شماره شناسایی ملی نروژ به MoBa پیوند داده شده بود، انجام شد (تعداد = ۱۲۵٬۰۱۶).
Lifelines هلند
Lifelines یک مطالعه کوهورت چندرشتهای، آیندهنگر و مبتنی بر جمعیت است که در یک طرح منحصربهفرد سه نسلی، سلامت و رفتارهای مرتبط با سلامت ۱۶۷٬۷۲۹ نفر را که در شمال هلند زندگی میکنند، بررسی میکند. این مطالعه از طیف وسیعی از رویههای تحقیقی برای ارزیابی عوامل زیستپزشکی، جامعهشناختی، رفتاری، فیزیکی و روانشناختی که به سلامت و بیماری جمعیت عمومی کمک میکنند، با تمرکز ویژه بر چندبیماری و ژنتیک پیچیده استفاده میکند. شرکتکنندگان از جمعیت شمالی هلند نمونهگیری شدند و نمونه نهایی حدود ۱۰٪ از جمعیت منطقه را در بر میگیرد. بین سالهای ۲۰۰۶ و ۲۰۱۳، پزشکان عمومی که به طور تصادفی انتخاب شده بودند، تمام بیماران ثبتشده خود در سنین ۲۵ تا ۴۹ سال را برای شرکت در مطالعه دعوت کردند. ما نمونه خود را به پاسخدهندگان ژنوتیپشده Lifelines که ≥۲۵ سال داشتند، محدود کردیم (تعداد = ۶۳٬۹۲۷). شاخصهای PGI و ده مؤلفه اصلی اول دادههای ژنتیکی به یک فایل داده اداری حاوی رشتههای تحصیلی (‘HOOGSTEOPLTAB 2022, v1’) که توسط آمار هلند نگهداری میشود، پیوند داده شد. به دلیل وجود دادههای گمشده در رشتههای تحصیلی، به ویژه برای نسلهای قدیمیتر، نمونه نهایی کل تعداد = ۳۶٬۵۰۱ بود.
کنترل کیفیت دادههای ژنتیکی
FinnGen
نسخه ۱۱ FinnGen شامل دادههای ژنوتیپ برای ۴۷۳٬۶۸۱ نفر پس از کنترل کیفیت (QC) است. در مجموع ۳۸۷٬۶۰۱ نفر با یک آرایه سفارشی FinnGen Thermo Fisher Axiom v2 ژنوتیپسنجی شدند. دادههای مربوط به ۸۶٬۰۸۰ نفر دیگر از مجموعههای قدیمی به دست آمد. اطلاعات بیشتر در https://finngen.gitbook.io/finngen-handbook/finngen-data-specifics/red-library-data-individual-level-data/genotype-data/affymetrix-chip-and-its-design موجود است.
MoBa
نمونههای خون از هر دو والدین در دوران بارداری و از مادران و کودکان (بند ناف) در هنگام تولد گرفته شد. دادههای آرایه ژنوتیپسنجی با کنترل کیفیت برای کل ۲۰۷٬۵۶۹ شرکتکننده منحصر به فرد MoBa اخیراً تولید شد. فازبندی و انتساب با IMPUTE4.1.2_r300.3 و با استفاده از پنل عمومی Haplotype Reference Consortium نسخه ۱.۱ به عنوان مرجع انجام شد. برای شناسایی یک زیرجمعیت با تبار مرتبط با اروپا، PCA با 1,000 Genomes فاز ۱ پس از هرس LD انجام شد. در طول کنترل کیفیت پس از انتساب، آستانههای زیر برای حذف SNP استفاده شد: امتیاز کیفیت انتساب (INFO) ≤۰.۸؛ فرکانس آلل مینور (MAF) <۱٪؛ نرخ فراخوانی <۹۵٪.
Lifelines هلند
نمونههای خون از شرکتکنندگان Lifelines در اولین بازدید ارزیابی جمعآوری شد. ژنوتیپها به عنوان بخشی از دو کوهورت جداگانه منتشر شدند. کوهورت CytoSNP بر روی آرایه Illumina CytoSNP-12v2 اندازهگیری شد که حدود ۳۰۰٬۰۰۰ SNP را اندازهگیری میکند. کوهورت UMCG Genetics Lifelines Initiative (UGLI) بر روی آرایه Infinium Global Screening Array MultiEthnic Disease اندازهگیری شد که حدود ۷۰۰٬۰۰۰ SNP را اندازهگیری میکند. دادههای با کنترل کیفیت برای هر دو کوهورت منتشر شد. گزارشهای QC برای CytoSNP و UGLI به ترتیب در http://wiki.lifelines.nl/doku.php?id=gwas و http://wiki.lifelines.nl/lib/exe/fetch.php?media=qc_report_ugli_r1.pdf موجود است. قبل از ساخت PGI و در هر کوهورت، ما SNPهای چندآللی، SNPهای با MAF < ۱٪، SNPهای با امتیاز INFO < ۰.۸ یا SNPهایی که در تعادل هاردی-واینبرگ نبودند (P < ۱۰-۶) را حذف کردیم. ما همچنین افرادی را با نرخ هموزیگوسیتی مقادیر ±۳ انحراف معیار حذف کردیم (حذف ۶۵۵ پاسخدهنده). ما همچنین ۱٬۲۸۹ پاسخدهنده از کوهورت CytoSNP را که در کوهورت UGLI نیز موجود بودند، حذف کردیم. پس از تکمیل تمام این مراحل QC، ما کوهورتهای CytoSNP و UGLI را در یک فایل داده واحد ادغام کردیم و فقط از SNPهایی استفاده کردیم که هر دو کوهورت پس از QC مشترک داشتند (در مجموع حدود ۶.۴ میلیون SNP).
معیارها
رشتههای تحصیلی گسترده
در هر سه کوهورت، ما دادههای ثبتی را در مورد کدهای رشته تحصیلی گسترده که نماینده رشته تحصیلی بالاترین مدرک هر فرد تا سال ۲۰۱۸ بود، استخراج کردیم. ما کدهای رشته را در تمام سطوح بالاترین مدرک (یعنی نه فقط در سطح دانشگاه) استخراج کردیم.
برای هماهنگسازی دادهها و تسهیل مطالعات تکراری آینده در کوهورتهای دیگر، ما کدهای رشته گسترده را از سیستمهای کدگذاری سطح ملی به کدهای رشته گسترده تعریفشده توسط ISCED 2013 (https://uis.unesco.org/sites/default/files/documents/international-standard-classification-of-education-fields-of-education-and-training-2013-detailed-field-descriptions-2015-en.pdf) تبدیل کردیم.
در FinnGen، ما از دادههای اداری پیونددادهشده از آمار فنلاند برای تعریف مدارک تحصیلی افراد استفاده کردیم. سوابق رشته تحصیلی فنلاند در https://www2.stat.fi/fi/luokitukset/koulutusala/ شرح داده شده است. در MoBa، ما از دادههای اداری پیونددادهشده از طبقهبندی استاندارد آموزش نروژ (NUS2000) استفاده کردیم. دادههای اداری کیفیت بالایی داشتند و دچار فرسایش نمونه نشدند. اطلاعات بیشتر در مورد کدگذاری NUS و تبدیل آن به ISCED در http://www.ssb.no/en/utdanning/norwegian-standard-classification-of-education موجود است. در مطالعه حاضر، دادههای گمشده فقط برای افرادی رخ میدهد که رشتههایشان دقیقاً با سیستم ISCED مطابقت ندارد، به عنوان مثال به دلیل بینرشتهای بودن (مثلاً ۱۶٬۰۰۰ فرد ژنوتیپشده در MoBa با مدارکی تحت عنوان «برنامههای بینرشتهای» و «مدارک شامل بهداشت و رفاه»). توجه داشته باشید که سوابق اداری هلند در مورد آموزش ناقص است، به طوری که ما معیارهای رشته تحصیلی را فقط برای ۵۶٪ از نمونه اصلی Lifelines در اختیار داشتیم (تعداد = ۳۶٬۳۷۳).
ما برای هر یک از کدهای تخصص رشته گسترده ISCED یک متغیر باینری ایجاد کردیم و افراد را اگر آن رشته را انتخاب کرده بودند ۱ و در غیر این صورت ۰ امتیاز دادیم. دسته ۰ شامل افرادی بود که برنامههای عمومی را مطالعه میکردند (که به خودی خود یک تخصص نیست). این شامل طیف وسیعی از مدارک، به عنوان مثال، دیپلم دبیرستان غیرتخصصی و آموزش مهارتهای توسعه حرفهای است.
ما همچنین متغیرهای سطح تحصیلات هماهنگشده را در تمام مجموعه دادهها ایجاد کردیم. ما اطلاعات سطح تحصیلات را از متغیر دقیقی که کد رشته را در بر داشت، گرفتیم و آن را به دستههای ISCED EduYears (سالهای تحصیلات تکمیلشده) تبدیل کردیم، مطابق با فراتحلیلهای GWAS بینالمللی.
دادههای جغرافیایی و والدین در MoBa
برای آزمایش اینکه آیا ارتباطات ژنتیکی منعکسکننده اثرات مستقیم هستند یا عوامل مخدوشگر ناشی از عوامل خانوادگی و جغرافیایی، ما از ثبتهای جمعیت و آموزش نروژ متغیرهای کمکی ایجاد کردیم. ما متغیرهای ساختگی برای شهرداریهای محل تولد (۲۱۶ کد که نماینده پایینترین سطح اداری نروژ هستند) برای کنترل محیطهای محلی مشترک و برای رشتههای تحصیلی والدین برای کنترل انتقال خانوادگی مهارتها، منابع و شبکههای خاص آموزشی ایجاد کردیم. پیوند و ساختار دادههای ژنتیکی-جغرافیایی قبلاً شرح داده شده است. اگرچه شهریه رایگان نروژ و جمعیت پراکنده با تنوع جغرافیایی در فرصتهای آموزشی، زمینه مفیدی برای این تحلیلها فراهم میکند، رویکرد ما ممکن است به طور کامل تأثیرات ناپایدار زمانی یا محلیتر را در بر نگیرد.
شاخصهای PGI در Lifelines هلند
برای اعتبارسنجی نتایج تحلیل GWA ما، ارتباطات بین شاخصهای PGI برای انتخاب رشته تحصیلی و انتخابهای واقعی رشته تحصیلی را در یک کوهورت مستقل آزمایش کردیم. شاخصهای PGI با استفاده از آمارهای خلاصه GWAS برای هر رشته مربوطه (که برای EA تصحیح نشده بود)، با استفاده از SBayesR در نرمافزار GCTB نسخه 2.05beta_Linux ساخته شدند. SBayesR از کوچکسازی بیزی استفاده میکند و به صراحت LD را برای تخمین اندازههای اثر SNP در حضور مارکرهای همبسته، با استفاده از امتیازات LD افراد با تبار مرتبط با اروپا که توسط Biobank بریتانیا تخمین زده شده، مدل میکند. برای آزمایش اثر مستقیم PGI، ما PGI میانه والدین را به عنوان یک متغیر کنترل اضافه کردیم. PGI والدین با استفاده از ترکیبی از ژنوتیپهای مشاهدهشده و منتسبشده (از والدین و خواهر و برادرها)، با استفاده از snipar ساخته شد. Snipar از دادههای خواهر و برادر یا دادههای والدین موجود برای انتساب ژنوتیپها برای والدین مشاهدهنشده استفاده میکند. PGI والدین را میتوان برای افرادی که حداقل یک خواهر یا برادر یا حداقل یک والد داشتند که در Lifelines نیز ژنوتیپ شده بودند، منتسب کرد (تعداد = ۱۷٬۷۰۵).
تحلیلها
فراتحلیلهای GWA
ما تحلیلهای GWA (GWAS) را برای ده فنوتیپ دوگانه رشته تحصیلی گسترده در MoBa و FinnGen انجام دادیم، با استفاده از مدلهایی که برای تحلیل کارآمد از نظر منابع فنوتیپهای مورد-شاهدی در مجموعه دادههای در مقیاس بیوبانک توسعه یافتهاند. در MoBa، از رویکرد FastGWA-GLMM (یک روش مدل خطی مختلط تعمیمیافته (GLMM) برای GWASهای در مقیاس بزرگ در نرمافزار GCTA نسخه 1.91.7beta (–fastGWA-mlm-binary)) استفاده شد. این یک مدل رگرسیون لجستیک با پیچیدگی اضافی استفاده از یک ماتریس پراکنده برای در نظر گرفتن خویشاوندی ژنتیکی متراکم در MoBa بدون حذف بستگان است. FastGWA-GLMM همچنین از روش تقریب نقطه زینی برای در نظر گرفتن تورم در آمارههای آزمون به دلیل عدم تعادل مورد-شاهدی استفاده میکند. در FinnGen، از گزینه باینری در نرمافزار REGENIE (نسخه 2.2.4) استفاده شد. REGENIE یک روش یادگیری ماشین است که رگرسیون ریج سراسر ژنوم را پیادهسازی میکند و از آزمون رگرسیون لجستیک فیرث برای در نظر گرفتن عدم تعادل مورد-شاهدی استفاده میکند. این دو روش از نظر نرخ مثبت کاذب و توان آماری به طور مشابه مؤثر هستند.
برای امکان فراتحلیل آمارهای خلاصه GWAS MoBa و FinnGen، ما QC و هماهنگسازی را انجام دادیم. ما واریانتهای با MAF پایین < ۱٪، کیفیت انتساب ضعیف (INFO < ۰.۸)، واریانتهای چندآللی و واریانتهای با آللهای مبهم (مثلاً آللهای غیر از A، C، G یا T) را حذف کردیم و وارونگی رشته و علامت را حل کردیم. مجموعه دادهها بر اساس chr:pos از ساختار ژنوم ۳۷ به عنوان شناسه SNP هماهنگ شدند. سپس فراتحلیلهای وزندهیشده بر اساس حجم نمونه از MoBa و FinnGen با استفاده از نرمافزار METAL انجام شد. ما از تنظیم SCHEME SAMPLESIZE برای تبدیل اندازههای اثر به نمرات z قبل از فراتحلیل استفاده کردیم.
برای شناسایی ارتباطات مستقل با اهمیت آماری در سطح ژنوم در نتایج فراتحلیل، ما خوشهبندی را با استفاده از پارامترهای استاندارد در نرمافزار FUMA انجام دادیم: leadP = ۵ × ۱۰-۸، gwasP = ۰.۰۵، r۲ = ۰.۶، r۲_۲ = ۰.۱، refpanel = 1KG/Phase3.
ما حجم نمونههای مؤثر خاص هر کوهورت را طبق مرجع محاسبه کردیم و سپس آنها را برای به دست آوردن مجموع حجم نمونههای مؤثر برای هر GWAS رشته تحصیلی جمع کردیم.
در MoBa، ما همچنین از FastGWA-GLMM برای تحلیلهای اضافی زیر استفاده کردیم: GWASهای ده رشته با کنترل برای سطح تحصیلات؛ GWASهای ده رشته با کنترل برای متغیرهای جغرافیایی و والدین؛ و GWASهای ده رشته به طور جداگانه برای مردان و زنان.
در تمام تحلیلهای GWAS (به جز تحلیلهای تفکیکشده بر اساس جنسیت)، ما جنسیت، سن، مؤلفههای اصلی تبار ژنتیکی (۲۰ در MoBa، ۱۰ در FinnGen) و شناسههای بچ را کنترل کردیم.
تحلیلهای GWAS-تفریقی با کنترل سطح تحصیلات
برای شناسایی سیگنالهای ژنتیکی مرتبط با رشتههای تحصیلی مستقل از سطح تحصیلات، ما از GWASهای تفریقی در Genomic SEM (بستهای در R-4.3.2) با استفاده از آمارهای خلاصه GWAS برای رشتههای تحصیلی و سطح تحصیلات استفاده کردیم. این رویکرد تجزیه کولسکی ژنومیک برای اولین بار برای ایجاد یک GWAS از مهارتهای غیرشناختی با «تفریق» مؤلفه ژنتیکی عملکرد شناختی از ارتباط هر SNP با سطح تحصیلات به کار رفت. در اینجا ما مؤلفه ژنتیکی سطح تحصیلات را از ارتباط هر SNP با یک رشته تحصیلی معین «تفریق» کردیم. برای هر یک از ده رشته، ما یک مدل کولسکی در سطح SNP برازش دادیم که دو متغیر مشاهدهشده (رشته و سطح تحصیلات) را بر روی دو متغیر پنهان (یک عامل مختص رشته و یک عامل سطح تحصیلات) رگرس کرد. کوواریانسهای بین متغیرهای پنهان روی ۰ ثابت شدند تا تمام واریانس توسط عوامل پنهان توضیح داده شود. برای جزئیات کامل مشخصات مدل و تصویری از مدل به شکل تکمیلی ۲۱ و یادداشتهای تکمیلی همراه آن مراجعه کنید.
تحلیلهای وراثتپذیری مبتنی بر SNP
سهم کلی SNPهای رایج در انتخاب رشته از آمارهای خلاصه GWAS با رگرسیون امتیاز LD، از طریق Genomic SEM نسخه 0.0.3f در R-4.3.2 تخمین زده شد. به طور متوسط، SNPهایی با امتیازات LD بالاتر (همبستگی بیشتر با سایر SNPها) به احتمال زیاد با یک واریانت علی واقعی همبسته هستند. به این ترتیب، هنگامی که آمارههای آزمون GWA (χ²) بر روی امتیازات LD رگرس میشوند، شیب خط، تخمینی از وراثتپذیری را ارائه میدهد که میتواند توسط SNPهای رایج توضیح داده شود. وراثتپذیری نشاندهنده درصد واریانس توضیح داده شده توسط واریانتهای ژنتیکی رایج است.
ما وراثتپذیریهای مبتنی بر SNP رشتههای تحصیلی را پس از کنترل برای EA به دو روش تخمین زدیم: از طریق GWASهای تفریقی و تعدیل فنوتیپی. ما توجه داریم که توصیه نمیشود تخمینهای وراثتپذیری را بر اساس رویکرد اول قرار دهیم، زیرا واریانس محیطی تعریف نشده است. با این وجود، ما تخمینهای وراثتپذیری مبتنی بر GWASهای تفریقی را گزارش کردیم زیرا آنها برای تفسیر مؤلفههای اصلی پاییندستی و تحلیلهای همبستگی ژنتیکی مرتبط هستند.
تحلیلهای ژنتیکی با تعدیل محل تولد و رشتههای والدین
برای مطالعه اینکه چه مقدار از ارتباطات ژنتیکی با انتخابهای رشته گسترده از طریق عوامل اجتماعی مشاهدهنشده در منطقه جغرافیایی که افراد در آن متولد شدهاند، واسطه میشود، ما تحلیلهای GWAS را فقط در MoBa تکرار کردیم، با کنترل کدهای شهرداری و کدهای رشته والدین به عنوان متغیرهای ساختگی و آزمایش برای وراثتپذیری تضعیفشده با رگرسیون امتیاز LD. ما این کار را به صورت تکراری انجام دادیم، ابتدا با کنترل دورترین عامل (شهرداری محل تولد)، سپس با افزودن رشتههای والدین. به دنبال روشهای قبلی که در Biobank بریتانیا به کار رفته بود، ما از Genomic SEM برای مقایسه تخمینهای وراثتپذیری SNP با و بدون کنترلها و با در نظر گرفتن وابستگی بین تخمینها استفاده کردیم. ما از تابع p.adjust در R با روش ‘fdr’ برای کنترل نرخ کشف کاذب (نسبت مورد انتظار اکتشافات کاذب در میان فرضیههای رد شده) استفاده کردیم و نتایج با P تعدیلشده < ۰.۰۵ را معنادار در نظر گرفتیم.
تحلیلهای PGI
در Lifelines هلند، ما ارتباطات PGI با رشتههای تحصیلی را با استفاده از رگرسیون لجستیک، با کنترل ده مؤلفه اصلی، چندجملهایهای سن، جنسیت و تعاملات آنها آزمایش کردیم. ما واریانس توضیح داده شده را با استفاده از R² کاذب مکفادن افزایشی کمیسازی کردیم. این به صورت 1-L1/L0 تعریف میشود، که در آن L1 درستنمایی مدل و L0 درستنمایی مدل فقط با یک عرض از مبدأ برازششده است. برای تخمین اثرات ژنتیکی مستقیم، ما کنترلهایی برای PGIهای منتسبشده والدین اضافه کردیم و اندازههای اثر درون-خانوادگی را با سطح جمعیت مقایسه کردیم، با بازههای اطمینان از ۱٬۰۰۰ تکرار بوتاسترپ و تصحیح بونفرونی (P < ۰.۰۰۵) برای تصحیح برای آزمایش ۱۰ فرضیه. ما همچنین ارتباطات PGI را با رشته تحصیلی همسر یا شریک زندگی آزمایش کردیم (تعداد = ۲۸٬۵۸۱؛ رگرسیون لوجیت)، و همسران یا شرکای زندگی را به عنوان اولین هموالد شناساییشده از طریق پیوند جمعیت هلند تعریف کردیم، اگرچه این ارتباطات احتمالاً الگوهای گستردهتر همسرگزینی همسان را منعکس میکنند تا اثرات ژنتیکی مستقیم بر انتخاب شریک زندگی.
ساختار ژنتیکی رشتهها: همبستگیهای ژنتیکی و GWASهای PCA
ما ساختار GWASهای رشتهها (نتایج فراتحلیل) را با محاسبه همبستگیهای ژنتیکی با استفاده از رگرسیون امتیاز LD در Genomic SEM نسخه 0.0.3f در R-4.3.2 بررسی کردیم. برای جفتهای صفات، حاصلضرب نمرات z GWA در هر SNP را میتوان بر روی امتیاز LD رگرس کرد، که تخمینی از همبستگی ژنتیکی بین دو صفت را ارائه میدهد.
ما ابعاد ارتباطات ژنتیکی با ده رشته تحصیلی را با اعمال PCA (با استفاده از eigen() در R-4.3.2) بر روی ماتریس استانداردشده همبستگیهای ژنتیکی بین رشتهها (پس از GWAS تفریقی برای حذف واریانس ژنتیکی EA) بررسی کردیم. برای به دست آوردن آمارهای خلاصه GWAS برای PC1 و PC2، ما سپس GWASهای PCA را طبق مرجع انجام دادیم (جزئیات بیشتر در https://annafurtjes.github.io/genomicPCA/). این رویکرد یک تابع فراتحلیل GWA را که برای فراتحلیل در چندین صفت طراحی شده است، تطبیق میدهد. به جای وزندهی بر اساس وراثتپذیری SNP هنگام میانگینگیری از اثرات SNP، بارهای استانداردشده بر روی مؤلفه اصلی مورد نظر، وزنها را فراهم میکنند. این تابع با تعدیل برای عرض از مبدأ رگرسیون امتیاز LD، همپوشانی نمونه را در آمارهای خلاصه GWAS در نظر میگیرد. آمارهای خلاصه GWAS حاصل برای دو مؤلفه مستقل رشته تحصیلی به ترتیب دارای حجم نمونه مؤثر ۱۰٬۴۱۳ و ۷٬۳۵۳ بودند (طبق مرجع).
ما به دلایل متعددی انتخاب کردیم که از PCA به جای تحلیل عاملی تأییدی (CFA) برای مطالعه ابعاد رشتههای تحصیلی استفاده کنیم. اول، PCA شامل فرضیات کمتری نسبت به CFA است. در حالی که CFA عوامل پنهانی را مدل میکند که فرض میشود نماینده صفات واقعی اندازهگیریشده توسط انتخاب رشته هستند، PCA به سادگی ابعاد دادهها را با یافتن محورهایی که حداکثر واریانس را توضیح میدهند، کاهش میدهد. علاوه بر این، CFA ممکن است نیاز به افزودن بارهای متقاطع تا حدودی موقتی بر اساس شاخصهای اصلاح برای دستیابی به برازش خوب داشته باشد، در حالی که PCA شامل ملاحظات برازش مدل نیست. دوم، تعداد محدود رشتههای ممکن (ده شاخص) PCA را مناسبتر میکند. CFA به طور ایدهآل برای مطالعه عوامل پنهانی طراحی شده است که میتوانند توسط تعداد گستردهای، به طور بالقوه بینهایت، از شاخصها اندازهگیری شوند، که در اینجا چنین نیست.
همبستگیهای ژنتیکی
ما همبستگیهای ژنتیکی بین عوامل پنهان رشتههای تحصیلی و ۹۶ فنوتیپ انسانی را با استفاده از رگرسیون امتیاز LD تخمین زدیم. ما از آمارهای خلاصه GWAS عمومی استفاده کردیم که توان آماری خوبی داشتند و طیف جامعی از حوزههای تنوع انسانی را پوشش میدادند. برای فهرست مراجع مطالعات GWAS با حجم نمونهها به جدول تکمیلی ۲۱ مراجعه کنید.
خلاصه گزارشدهی
اطلاعات بیشتر در مورد طراحی پژوهش در خلاصه گزارشدهی Nature Portfolio که به این مقاله پیوند داده شده است، موجود است.